Explainable AI in Banking: Why Every Automated Decision Will Need a Reason by December 2026
Australian financial services face five regulatory deadlines that put a hard floor under explainable AI. Here's what the compliance calendar looks like, why your current ML stack won't pass, and what to do about it.


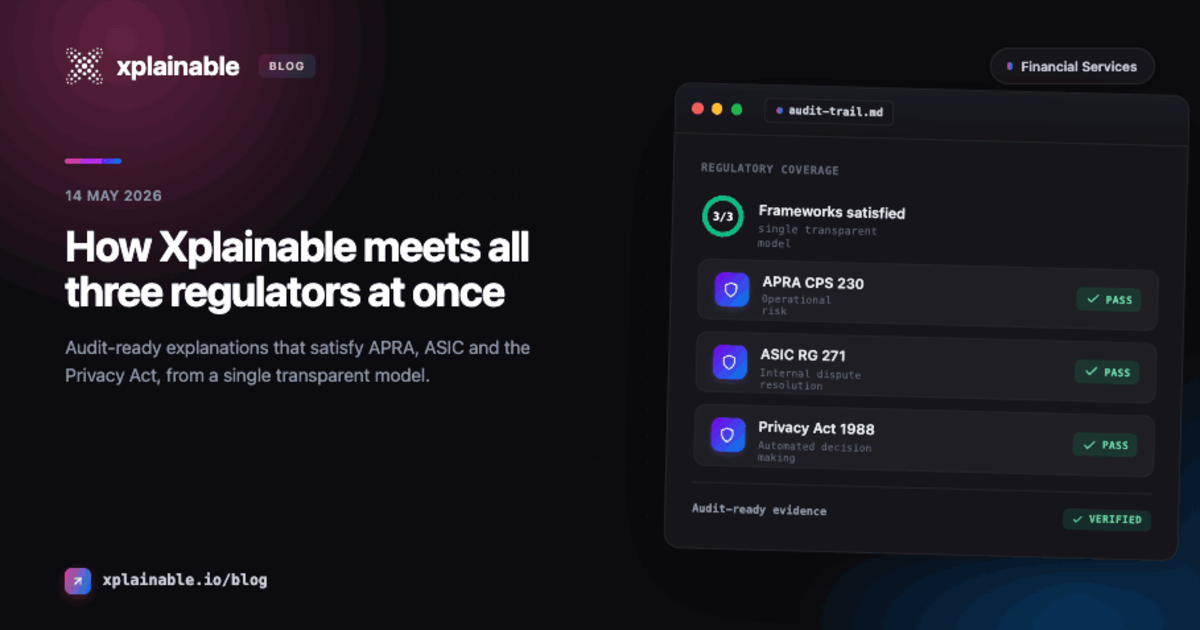
On 10 December 2026, every automated decision that materially affects an Australian customer will require a reason. Not a confidence score. Not a SHAP waterfall chart. A reason a collections officer can read, a compliance team can audit, and AFCA can review.
This isn't a discussion paper. The Privacy and Other Legislation Amendment Act 2024 is law. The penalties are $50 million per breach, or 30% of adjusted turnover, whichever is larger.
For banks, non-bank lenders, BNPL providers, and insurers running machine learning in production, this creates a problem that most existing ML stacks were never designed to solve.
The Compliance Calendar Financial Services Can't Ignore
Five regulatory deadlines are converging in an 18-month window:
This isn't a single regulation. It's five overlapping requirements from three different regulators (APRA, ASIC, and the OAIC), each testing a different part of your decisioning stack.
The buying environment is unusually concentrated. 30+ Australian institutions are each writing a compliance remediation plan right now. They need a tool, not a consultant.
The Precedents Are Already Being Set
Regulators aren't waiting for December 2026 to act. The enforcement pattern is already clear:
- $40M : IAG/NRMA judgement for an algorithmic pricing decision. The Federal Court penalised a Tier-2 insurer for a model output it couldn't explain to the customer.
- $15.5M : NAB's hardship penalty from ASIC. The regulator is now actively pursuing lenders whose automated systems can't produce auditable reasons for hardship rejections.
- Resimac (March 2025) : The first non-bank lender ever sued by ASIC for hardship failures. Case management hearing was scheduled for March 2026.
These aren't edge cases. They're the new baseline. If your model can't explain why it rejected a hardship application, you're exposed today, not just in December 2026.
Why SHAP and LIME Won't Get You There
Most financial services teams running ML in production have bolted SHAP or LIME onto their existing models. It's the obvious first move. It's also the wrong one for regulatory compliance.
Here's why:
The Translation Gap
SHAP produces feature attribution values. A data scientist can interpret them. An operations team member rewriting reason codes for an AFCA response cannot.
When a collections officer needs to write "Dear Mr Smith, the primary factors in our decision were your current debt-to-income ratio and a recent missed payment," a SHAP waterfall chart doesn't help. Someone has to translate it manually. Every rejection. Every time.
Research published in Frontiers in AI found that while SHAP and LIME are the state-of-the-art in post-hoc explainability, LIME suffers from potential instability issues, and KernelSHAP's computation time makes it unscalable for datasets with many features.
The Compliance Gap
SHAP and LIME are post-hoc methods. They approximate what a model did after the fact. They don't change the model's architecture. This creates three problems for regulated environments:
- Explanations can disagree with each other. SHAP and LIME can produce different attributions for the same prediction. Which one do you put in the AFCA response?
- No real-time explanations. Post-hoc methods require a separate computation step. In production systems processing thousands of decisions per hour, this adds latency and infrastructure cost.
- No audit trail by default. The explanation is generated separately from the prediction. There's no guarantee they stay linked in your logging pipeline.
The Calendar Gap
If your plan is to build an in-house explanation layer on top of your existing XGBoost or LightGBM models, the timeline doesn't work. A January 2026 build kickoff, assuming you can hire a senior financial services data scientist at $400K or more per year, lands in production roughly three months after the December deadline.
Three different ways to miss the same deadline. Each fails a different regulator's test.
What Inherently Explainable AI Looks Like
The alternative to post-hoc explanation is inherent interpretability: models where the explanation is a structural property of the architecture, not an approximation bolted on afterwards.
This is what xplainable was built for.
Instead of training a black-box model and then asking "why did it say that?", an inherently explainable model produces the prediction and its drivers in the same computation. Per-feature attribution is baked into the model architecture. There's nothing to approximate.
Native Explainability
Every prediction ships with the features that drove it, their direction, and their magnitude:
This isn't a separate SHAP computation. It's the model's native output. The same inference call that produces the score produces the drivers.
Costed Recommendations
Beyond explaining what drove a decision, xplainable's scenario analysis shows what would change the outcome:
- Recommended action: Hardship plan
- Expected outcome: +$3,200 recovery
- Confidence: 84%
- Top drivers: Tenure (up), cohort arrears (down), prior recovery history (up)
This maps directly to APP 1.7-1.9 requirements: the customer gets a reason, the operations team gets an action, and the compliance team gets an audit trail.
Customer-Readable Reason Codes
The explanation isn't just machine-readable. It generates customer-facing language that maps to RG 271 requirements:
One click. No manual translation. No operations team member rewriting SHAP outputs into plain English.
Rapid Refitting
Regulated models need to be updated as conditions change. Traditional ML requires full retraining, which means re-validation, re-testing, and re-deployment.
xplainable supports rapid refitting: updating parameters on individual features without retraining the entire model. A weekly model update can adjust four features in minutes, not days. The audit trail shows exactly what changed and when.
No Accuracy Tradeoff
The historical objection to interpretable models is that they sacrifice accuracy. Logistic regression is explainable but often underperforms gradient-boosted trees on complex financial data.
xplainable breaks this tradeoff. Independent benchmarks show glass-box xplainable models matching the performance of XGBoost and LightGBM on equivalent datasets, while producing native explanations at sub-millisecond inference speeds.
You don't have to choose between a model your regulator can audit and a model that performs well in production.
The Three Levels of Explanation Regulators Need
Different stakeholders need different views of the same model. xplainable provides three levels of explanation from a single model:
-
Global explanations tell the board and the regulator how the model works overall. Which features matter most? Are there patterns that suggest bias? This maps to CPS 230 model risk governance.
-
Regional explanations show how the model behaves for specific segments. How does it treat customers in hardship differently from current customers? This is what ASIC looks at when investigating systemic issues.
-
Local explanations answer the individual question: why was this specific customer declined? This is what the AFCA reviewer reads. This is what the Privacy Act ADM rules require from December 2026.
All three come from the same model, the same architecture, and the same inference call. No separate tooling. No approximation drift.
What This Means for Your December 2026 Deadline
If you're running ML in collections, credit decisioning, claims, or hardship assessment at an Australian financial services institution, the compliance window is narrowing.
The question isn't whether you need explainable AI. The regulation answers that. The question is whether your current stack can produce the explanations your regulator, your operations team, and your customers will demand.
Ready to see what audit-ready AI looks like on your data? We'll run three explainable model outputs against a synthetic version of your decisioning cohort and walk you through the audit trail end-to-end. No commitment. 30 minutes.
Book a working session