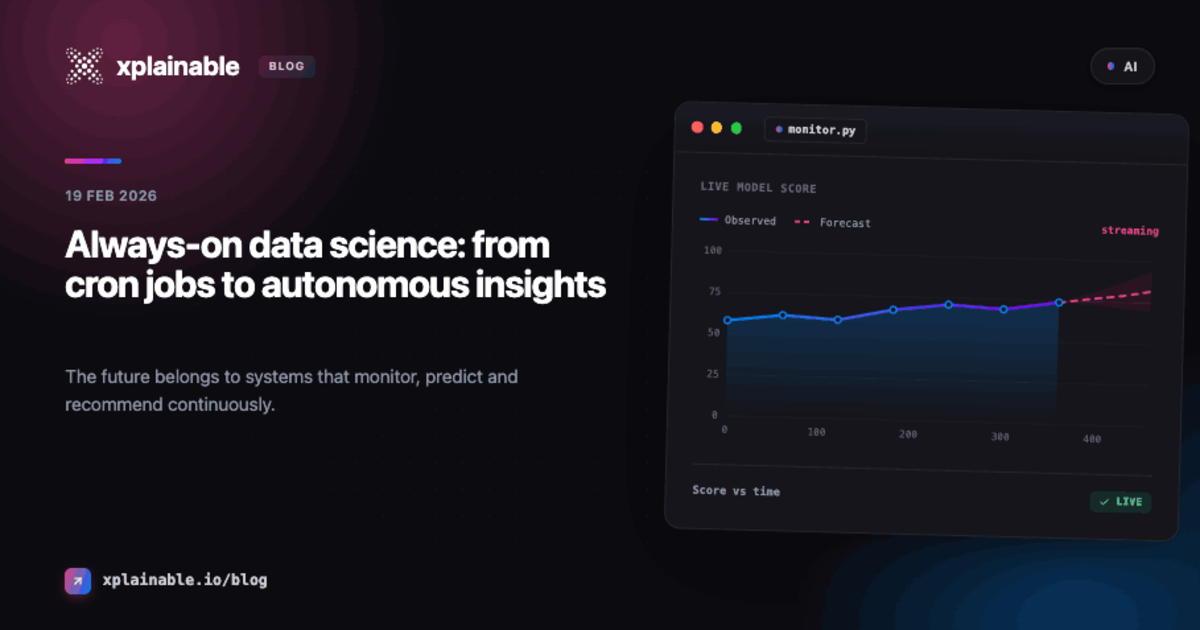
Always-On Data Science: From Cron Jobs to Autonomous Insights
The era of running a model once and waiting for someone to ask a question is ending. The future belongs to systems that monitor, predict, and recommend continuously, without human prompting.

There is a familiar rhythm to most data science work. Someone asks a question. An analyst builds a model. The model produces an answer. The answer gets put into a slide deck. Everyone moves on until the next question.
This cycle has a fundamental flaw: it is entirely reactive. The model only runs when someone thinks to ask. The insight only surfaces when someone knows what to look for. And in the gap between questions, the data keeps changing, customers keep churning, and opportunities keep slipping past.
2026 is the year this rhythm breaks. A convergence of autonomous agents, scheduled pipelines, and explainable machine learning is making "always-on" data science not just possible, but practical.
The Cron Job: Automation's Humble Beginning
Every data engineer knows the cron job. That five-field expression that tells a server to do something at a specific time: retrain a model at midnight, refresh a dashboard at 6am, run an ETL pipeline every hour.
Cron jobs were the first step toward autonomous data science. They removed the human from the loop for when something runs. But they did nothing about what runs, why it matters, or what to do about it.
A cron job can tell you that your model ran at 3am. It cannot tell you that the predictions shifted dramatically, that a specific customer segment is deteriorating, or that changing one input variable would flip a high-risk prediction to low-risk.
Scheduled pipelines solved the timing problem. They did not solve the insight problem.
OpenClaw and the Rise of the Autonomous Agent
The explosion of interest in OpenClaw (originally ClawdBot, then Moltbot) in early 2026 has put a spotlight on what autonomous agents can actually look like. With over 145,000 GitHub stars and integrations across WhatsApp, Slack, Telegram, and more, OpenClaw represents a new paradigm: AI that acts without being asked.
OpenClaw's cron job feature is particularly revealing. Users configure scheduled tasks, and the agent executes them proactively: daily briefings combining weather, calendar, and news. Stock monitoring with threshold-based alerts. Email categorisation and draft responses. The system transforms from a passive chatbot into an always-on assistant.
The parallel to data science is direct. What if your machine learning models did not wait for someone to click "Run"? What if they monitored incoming data continuously, flagged anomalies the moment they appeared, and told you exactly what to do about them?
From Passive Models to Active Monitors
The industry is converging on autonomous ML pipelines — systems that self-manage model training, deployment, monitoring, and retraining with minimal human intervention.
The progression looks like this:
Most organisations are stuck between stages one and two. The gap between stage two and stage four is where the real value lives.
Predictions Are Not Enough
Here is the uncomfortable truth about most production ML systems: they generate predictions that nobody acts on.
A churn model predicts that Customer #4,871 has a 78% probability of leaving. So what? The prediction alone does not tell the account manager why the customer is at risk or what specific action might change the outcome.
This is where explainability transforms from a compliance checkbox into an operational tool.
With xplainable's inherently interpretable models, every prediction comes with a complete breakdown of what is driving it. Not a post-hoc approximation from SHAP or LIME, but the actual feature contributions baked into the model's architecture. The system can tell you:
- Customer #4,871 is high-risk primarily because their support ticket volume increased 340% in the last 30 days
- Their product usage dropped from 12 sessions/week to 3
- Their contract renewal date is 45 days away
More importantly, xplainable's scenario analysis can tell you what would change the outcome:
If support ticket resolution time decreases from 72 hours to 24 hours, the predicted churn probability drops from 78% to 41%. If a customer success check-in is logged within 7 days, it drops further to 29%.
This is not a prediction. This is a recommendation. And it changes the economics of the entire system.
Always-On Monitoring with xplainable
xplainable's new monitoring functionality brings this concept to life. Monitors connect directly to live data sources, including PostgreSQL, MySQL, Snowflake, BigQuery, Google Sheets, and Amazon S3, and run predictions against incoming data on a configurable schedule.
The system supports two processing modes:
- Full Dataset mode processes every row on each run, ideal for complete rescoring
- Incremental mode tracks a watermark column (such as a timestamp or auto-incrementing ID) and only processes rows added since the last run
When new data arrives, the monitor fetches it, runs predictions through the deployed model, evaluates alert rules, and notifies the team, all without a human clicking a button.
python# What used to require a data engineer, a scheduler, # and a custom notification pipeline: from xplainable.core.models import XClassifier model = XClassifier() model.fit(X_train, y_train) # Deploy once. Monitor continuously. # New data arrives > predictions generated > team notified # Every prediction is explainable. Every alert is actionable.
The critical difference from a traditional cron job is what happens after the predictions are generated. Each prediction carries its full explanation: which features contributed, by how much, and in which direction. Alert rules can trigger on thresholds, trends, or volume. And the scenario analysis capability means the system does not just tell you what is predicted, it tells you how to change it.
The Autonomous Insight Loop
Put this all together and you get something genuinely new: a closed loop where data flows in, predictions flow out, explanations are generated, and recommendations are surfaced, all continuously.
- Data arrives from a connected integration source
- Predictions are generated against the deployed model
- Explanations are computed for every prediction in real-time
- Alert rules fire when thresholds are breached or trends shift
- Notifications reach the team via in-app alerts
- Scenario analysis shows what actions would change the outcome
No one had to ask a question. No one had to open a notebook. No one had to remember to check the dashboard.
This is what "always-on" data science actually means. Not just a model running on a schedule, but an intelligent system that monitors, predicts, explains, and recommends, continuously.
From Reactive to Proactive: The Cultural Shift
The technology is ready. The harder challenge is cultural.
Most data science teams are structured around the request-response model: business stakeholder asks a question, data team answers it. Always-on systems invert this relationship. The data team builds the monitor once, and the system proactively surfaces insights to stakeholders before they know to ask.
This requires trust. Stakeholders need to trust that the alerts are meaningful, not noise. They need to trust that the explanations are accurate, not approximations. And they need to trust that the recommendations are actionable, not theoretical.
Inherent interpretability is not a nice-to-have in an always-on system. It is the foundation. If your autonomous monitor cannot explain why it is alerting you, it is just an expensive alarm clock.
This is precisely why the explainability built into xplainable's architecture matters for this paradigm shift. When a monitor triggers an alert at 2am, the team opening that notification needs to immediately understand what changed, why it matters, and what to do. Post-hoc explanation methods that require separate model fitting or sampling cannot deliver this in real-time. Inherent interpretability can.
What Comes Next
The trajectory is clear. Just as OpenClaw moved personal AI from "answer when asked" to "act when needed," production data science is making the same leap.
The cron job got us scheduled execution. Active monitoring gets us event-driven predictions. Explainable AI gets us autonomous recommendations. Combined, they create systems where insight is not something you go looking for. It finds you.
The question is no longer "What does the data say?" It is: "Is anyone listening when the data speaks?"
With always-on monitoring and explainable predictions, the answer can finally be yes.
xplainable's monitoring functionality supports direct connections to PostgreSQL, MySQL, Snowflake, BigQuery, Google Sheets, Salesforce, and Amazon S3, with both full-dataset and incremental processing modes. Book a demo to see always-on monitoring with explainable predictions in action.