Xplainable vs SHAP: Embracing Transparency in Machine Learning
A comprehensive comparison of built-for-explainability versus surrogate model approaches

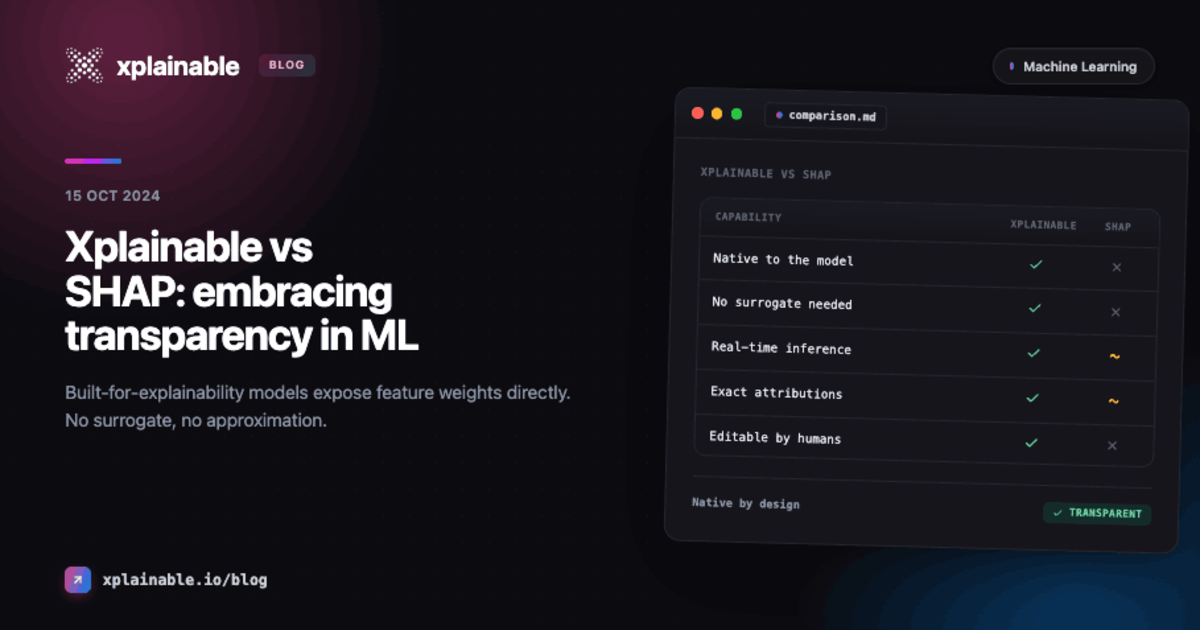
Xplainable vs SHAP: choosing explainability that actually drives decisions
Short version: SHAP is a powerful, widely used post-hoc attribution method. It is great for inspecting complex models, but it is often approximate outside of trees, is sensitive to data choices, and does not give you an optimisation framework. Xplainable centres on interpretable-by-construction models and workflows, so the same objects that predict are the ones you inspect, simulate and optimise.
Why this comparison matters
If your goal is to ship decisions, explanations must be stable, reproducible and directly usable in what-if analysis and constraint-aware optimisation. Post-hoc tools like SHAP explain the model you already trained, whereas Xplainable starts with models whose structure is the explanation, which cleanly supports scenario testing and prescriptive moves.
What SHAP actually provides
SHAP (SHapley Additive exPlanations) attributes a prediction to features using game theory. In general, computing exact Shapley values is hard, so most model-agnostic uses rely on sampling-based approximations such as KernelSHAP. For tree ensembles, specialised algorithms like TreeSHAP compute exact values efficiently. SHAP helps you understand model behaviour, but it does not solve for the best action under constraints.
Links: SHAP docs · KernelSHAP analysis · Improving KernelSHAP · TreeSHAP overview
Important limitations to keep in mind
-
Approximation outside trees: KernelSHAP and similar methods estimate Shapley values with sampling or regression, which introduces variance and tuning choices.
-
Sensitivity to representation and background data: SHAP attributions can change with feature encoding and independence assumptions, which can even be exploited.
-
Potentially misleading for decision makers: Peer-reviewed critiques show ways SHAP can convey misleading information in practice, especially when users conflate attribution with causality.
-
No built-in optimisation: SHAP explains a prediction after the fact. It does not provide a native way to impose business constraints, run counterfactual scenarios at scale, or compute an optimal policy. (This is by design, not a bug.) Docs emphasise explanation APIs, not prescriptive optimisation.
To be fair, TreeSHAP is both exact and fast for tree models, and with GPU or algorithmic refinements it scales further. If you must keep a black-box tree ensemble and want faithful local attributions, TreeSHAP is state-of-the-art. It still does not turn explanations into an optimisation engine.
What Xplainable provides instead
Xplainable is built around transparent models and decision-first workflows: you train interpretable structures, view the learned shape functions, and then run scenario analysis and batch optimisation that respect real-world constraints. This design maps closely to modern Generalised Additive Models (GAMs) and shape-constrained GAMs, which deliver smooth, monotone or convex effects per feature that are both legible and mathematically well-behaved for governance and control.
Links: GAM references and tutorials: Wood & Pya 2014 · Pya & Wood 2013, Statistics and Computing · Journal of the Royal Statistical Society B · SCAM package · Recent optimisation approach to shape-constrained GAMs
Why this matters for decisions
-
The model is the explanation: predictions are a baseline plus per-feature functions, so the same objects you audit are the ones you deploy. No surrogate needed.
-
Constraint-ready: monotonicity and curvature constraints make it straightforward to encode policy and domain knowledge directly in the model, which stabilises behaviour at the edges and prevents gaming.
-
Scenario analysis and optimisation: additive, shape-constrained structures let you simulate what-if changes and search for optima under explicit constraints, which is exactly what operations and product teams need.
Side-by-side: explanation vs decision workflow
-
SHAP path: explanations are after prediction. There is no native optimisation step; teams bolt on custom tooling and must translate noisy, sensitive attributions into actions.
-
Xplainable path: explanation is in the prediction mechanism, so simulations and constrained optimisation are first-class citizens.
A practical decision checklist
Choose SHAP when:
-
You already committed to a complex model and need human-readable attributions quickly.
-
Your model is a tree ensemble and you want exact local explanations via TreeSHAP.
Links: TreeSHAP explainer · GPU TreeSHAP · Linear TreeShap, NeurIPS 2022
Choose Xplainable when:
-
You want explanations without approximation and a single source of truth for both prediction and interpretation.
-
You must optimise under policy or operational constraints and need stable, monotone or convex response curves you can defend.
-
You care about governance and reproducibility across teams and reports.
Links: Shape-constrained GAMs in practice · JRSS-B additive shape constraints
Common misconceptions
- “SHAP is always approximate.”
Not always. TreeSHAP is exact for trees. The general model-agnostic case is approximate. Use the right tool for the model class.
- “Explanations equal causality.”
No. SHAP scores can mislead when features are dependent or poorly specified, and they are sensitive to encodings and background assumptions. Do not treat attributions as interventions.
- “You can use SHAP to optimise decisions.”
SHAP does not provide a prescriptive engine. It explains predictions. Optimisation requires a separate model or solver and clear constraints; Xplainable bakes these into the modelling workflow.
Closing thought
If your primary question is why did this model say that, SHAP — especially TreeSHAP for ensembles — is excellent. If your primary question is what should we do next under policy and operational constraints, choose Xplainable. By making explanation the model itself, you gain stable shape functions for audit and the natural bridge to scenario analysis and optimisation, which SHAP does not provide.